扩散模型笔记
扩散模型的灵感来自于非平衡热力学。他们定义了一个扩散步骤的马尔可夫链,慢慢地向数据添加随机噪声,然后学习反向扩散过程,从噪声中构建所需的数据样本。与VAE或flow模型不同,扩散模型的学习过程是固定的,潜变量具有高维数(与原始数据相同)。通俗一点来说就是,现在我们的目标是用随机噪声生成原始数据,然而一步到位不太可能,于是我们将过程拆解,先分析原始数据是怎么一步步变为随机噪声的,再研究如何从噪声一步步恢复原样本。(拆楼与建楼)
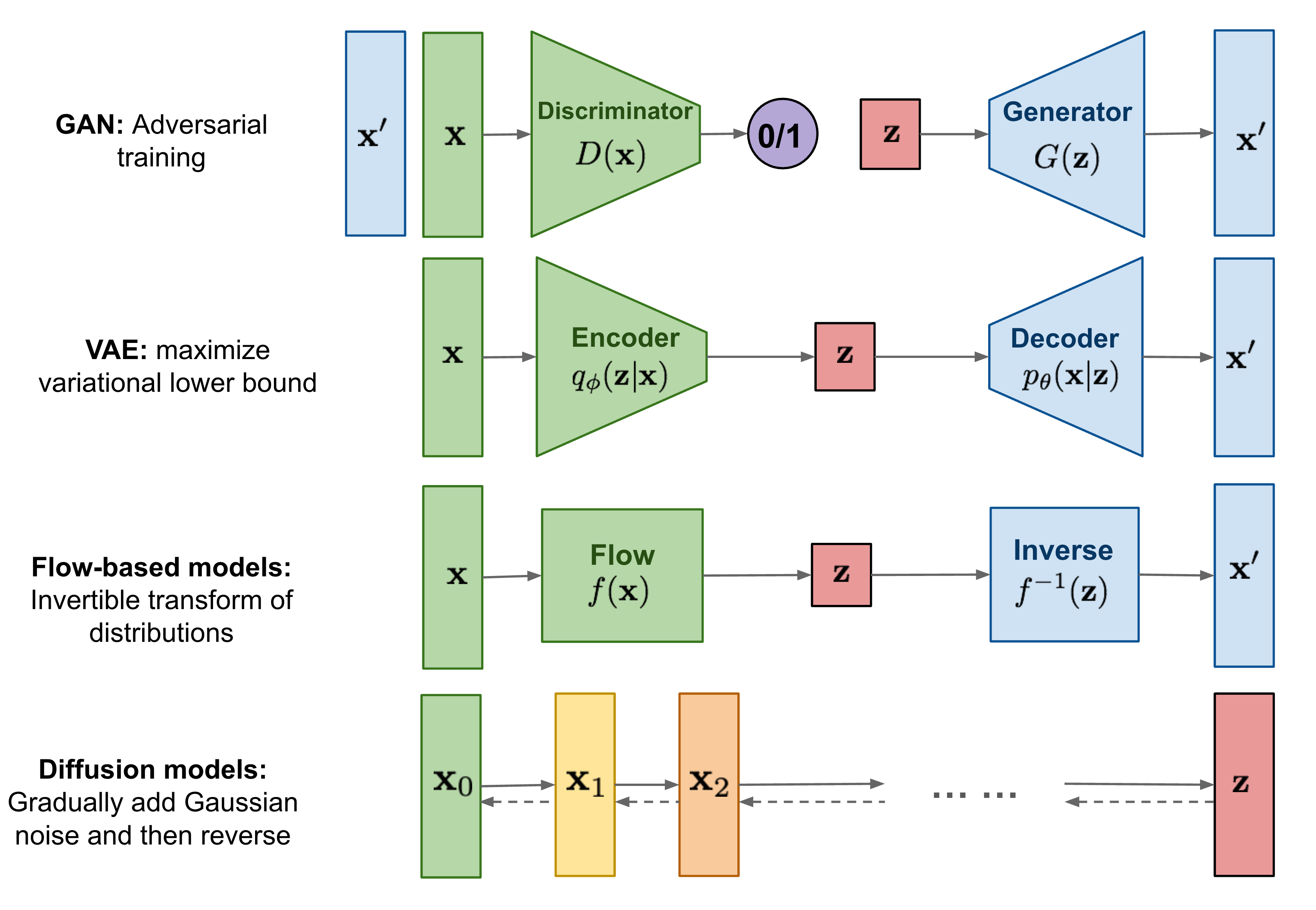
前向扩散过程
给定一个从真实数据分布中采样的数据点 x0∼q(x) ,定义一个前向扩散过程,在这个过程中我们逐步向样本中分 T 步添加少量的高斯噪声,产生一系列噪声样本 x1,…,xT ,步长由一系列超参数 βt 控制 {βt∈(0,1)}t=1T ,通常我们会慢慢地增加 βt ,也就是开始加入很小的噪声,随着时间步增加,加入的噪声慢慢变大:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
数据点 x0 随着时间步 t 的增加逐渐变的模糊不可分辨。最终当 T→∞ ,xT 等价于各向同性高斯分布
下面我们就来具体看一下前向过程,前向过程一个非常不错的性质是我们可以取样在任意时间步 t 对应的 xt (通过重参数化技巧),定义 αt=1−βt 和 αˉt=∏i=1tαi :
xtq(xt∣x0)=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ=N(xt;αˉtx0,(1−αˉt)I) ;其中 ϵt−1,ϵt−2,⋯∼N(0,I)
正态分布 N(0,σ12I) 和 N(0,σ22I) 的叠加分布为 N(0,(σ12+σ22)I) 。
逆扩散过程
有了前向扩散过程,即加噪声破坏原始数据,现在我们考虑如何学习从噪声 xT∼N(0,I) 开始一步步恢复数据,即学习 q(xt−1∣xt) ,那么最终我们就可以重建原数据。可以把逆扩散过程也建模为高斯,实际上如果 βt 足够小,q(xt−1∣xt) 也将是一个高斯分布。不过,估计 q(xt−1∣xt) 并是一件容易的事情,因为它需要使用整个数据集,需要学习一个模型来近似这些条件概率以便进行逆扩散过程:
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
我们首先尝试计算逆扩散过程条件概率,逆扩散条件概率在已知 x0 的条件下是可以计算的:
q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
使用贝叶斯公式以及马尔可夫性:
q(xt−1∣xt,x0)=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
其中 C(xt,x0) 是和 xt−1 无关的常数。根据高斯分布的均值方差形式,通过配方法,上式可以参数化为:
β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
此外,由于 x0=αˉt1(xt−1−αˉtϵt) ,带入上式可得:
μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)
自此关于扩散模型的前向扩散过程和逆扩散过程已经推导完毕。此时虽然我们有了形式化的逆扩散条件概率,但是其中的噪音量我们是不知道的。
在原 DDPM 论文中,逆扩散过程方差项为定值,均值项含噪音 ϵt,如果我们能够知道每一步的噪音,就可以去噪还原每一步的数据了,但它显然无法用公式求解,所以考虑:
- 训练一个模型预测每一步的噪音,或者直接预测出每一步数据
- 我们需要估计每个时刻的噪声,要恢复要去噪就要知道扩散过程究竟加了多少噪音
- 模型的输入参数有两个:当前时刻 t,和 xt ;ϵt 是噪声标签
简言之,前向过程就是提供噪声标签的过程。反向过程就是在拟合这个噪声。
为了设计一个合理的学习函数(损失函数),观察使用网络 θ 还原原数据 x0 过程中的对数似然变分下界:
−logpθ(x0)Let LVLB≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0)
这个结果看起来很突兀,实际上我们也可以从詹森不等式角度得到:
LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
有了似然函数的界还不够,我们需要一个可解析计算的界来帮助我们设计损失函数,为了将上式中的每一项转化为可解析计算的,上式目标可以进一步重写为几个 KL 散度和熵项的组合:
LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LTDKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0−logpθ(x0∣x1)]
LVLB=Eq[LTDKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0−logpθ(x0∣x1)]
让我们分别标记变分下界损失中的每个分量:
LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
LT 是常数,因为 T 步的 xT 是纯高斯噪音,而 q 无可学习参数。L0 情况暂时忽略,总之可以当常数看。重点是 Lt 项。
从 Lt 到训练损失函数
回想一下,我们需要学习一个神经网络来近似逆向扩散过程中的条件概率分布:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
方差项再 DDPM 中是定值,于是实际上是训练 μθ 来预测 μ~t=αt1(xt−1−αˉt1−αtϵt) ,因为 xt 在训练中是已知的,实际上我们只需参数化噪声项:
μθ(xt,t)Thus xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))=N(xt−1;αt1(xt−1−αˉt1−αtϵθ(xt,t)),Σθ(xt,t))
损失项 Lt 可以被写为最小化预测均值与真实均值之间的误差:
Lt=Ex0,ϵ[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,ϵ[2∥Σθ∥221∥αt1(xt−1−αˉt1−αtϵt)−αt1(xt−1−αˉt1−αtϵθ(xt,t))∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(xt,t)∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
最终转换为噪声项之间的差值。
简化损失函数
根据经验,Ho等人发现,训练扩散模型使用忽略加权项的简化目标效果更好:
Ltsimple=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(xt,t)∥2]=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
最终的损失函数:
Lsimple=Ltsimple+C
其中 C 为常数。

加速扩散模型采样 DDIM
由于DDPM加噪基于马尔科夫链过程,那么在去噪过程过程也必须基于这个过程,遵循马尔可夫链的逆扩散过程从 DDPM 生成样本非常慢。
DDPM 的损失函数 Lsimple 只依赖边缘分布 q(xt∣x0) 而不直接依赖联合分布 q(x1:T∣x0) ,就是说联合分布形式并不影响我们训练 DDPM 的过程,DDPM 中联合分布恰好可以按马尔可夫性拆分为一个个条件分布,那么是否存在非马尔可夫的加噪过程,或者说更一般的加噪过程呢,确实存在,所以我们可以设计一种非马尔可夫加噪过程,并且我们能保证 q(xt∣x0) 与 DDPM 中保持一致,也就是训练可以共享同样的目标函数。换句话说,只要 q(xt∣x0) 已知并且是高斯分布,那么就可以使用 Lsimple 来训练模型。
在 DDPM 中,由于马尔可夫性,有 q(xt∣xt−1,x0)=q(xt∣xt−1) ,如果我们能够吧 q(xt∣xt−1,x0) 推广到更一般的形式,并且保证 q(xt∣x0) 形式不变(高斯),那么我们就能在不改变 DDPM 前提下,只需重写采样函数。
论文就给出了一种非马尔可夫前向扩散过程的公式和后验概率表达式,而该后验概率恰好满足 DDPM 中的边缘分布 q(xt∣x0) :(证明略)
qσ(x1:T∣x0):=qσ(xT∣x0)Πt=2Tqσ(xt−1∣xt,x0)
并且有 qσ(xt−1∣xt,x0) :
xt−1qσ(xt−1∣xt,x0)=αˉt−1x0+1−αˉt−1ϵt−1=αˉt−1x0+1−αˉt−1−σt2ϵt+σtϵ=αˉt−1x0+1−αˉt−1−σt21−αˉtxt−αˉtx0+σtϵ=N(xt−1;αˉt−1x0+1−αˉt−1−σt21−αˉtxt−αˉtx0,σt2I)
由于 q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI),所以:
β~t=σt2=1−αˉt1−αˉt−1⋅βt
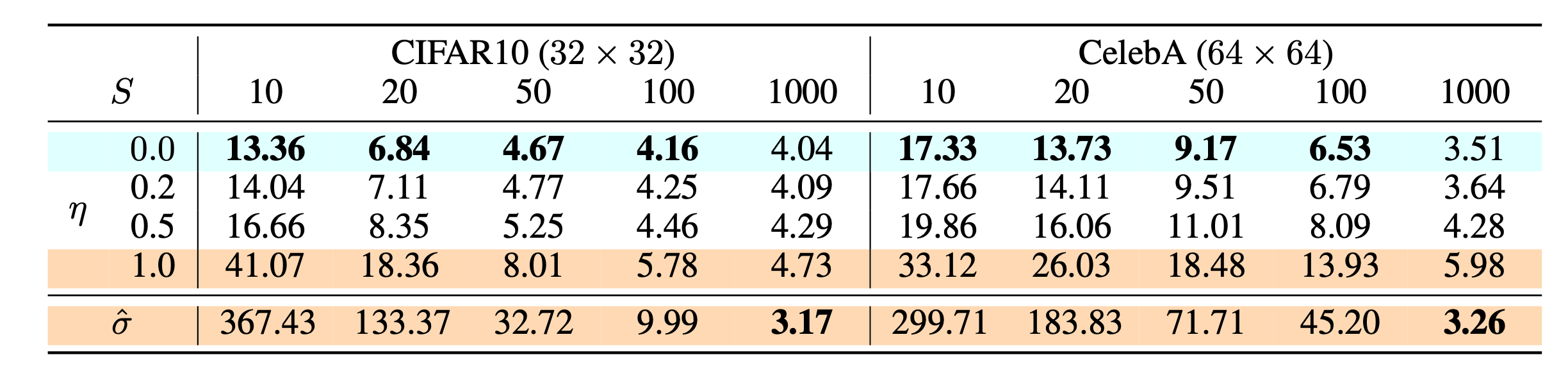
令 σt2=η⋅β~t ,于是我们可以调整 η∈R+ 作为控制采样随机性的超参数,特殊地 η=0 可使采样过程具有确定性。这就是 DDIM 名称的由来,它确定性地将噪声映射回原始数据样本。DDPM 中 η=1 。
注意: 扩散模型加速采样的本质是提取预估了 x0,用 x0 算采样结果。
加速采样: respacing
在生成过程中,只需要采集 S 步扩散 {τ1,…,τS} 的子集,inference 过程变为子序列采样:
qσ,τ(xτi−1∣xτt,x0)=N(xτi−1;αˉt−1x0+1−αˉt−1−σt21−αˉtxτi−αˉtx0,σt2I)
使用 DDIM,可以将扩散模型训练到任意数量的前向步骤,但在生成过程中只需要在步骤子集中进行采样即可。也就是我们不必在完整的时间序列进行解码过程,只需要在它的子序列上去做即可。
分数扩散模型 NCSN
D3PM

参考文献
DDPM
DDIM
NCSN
Q.E.D.


